SO-Arm + LeRobot (VR training)

Project overview: I built and trained a low-cost SO-100 robotic arm using Hugging Face's LeRobot framework. The goal wasn't to chase a perfect benchmark, but rather to build a reliable 'launchpad' for longer-horizon Physical AI experiments. I wanted to prove an end-to-end pipeline I could easily iterate on: hardware assembly, data capture, a smooth teleoperation UX, model training, and physical evaluation.
- Printed and assembled the SO-100 arm hardware.
- Set up LeRobot on a £60 Linux PC (an eBay special) to handle the local control and data pipeline.
- Built a VR headset control bridge to teleoperate and collect data without needing to build a second physical 'leader' arm.
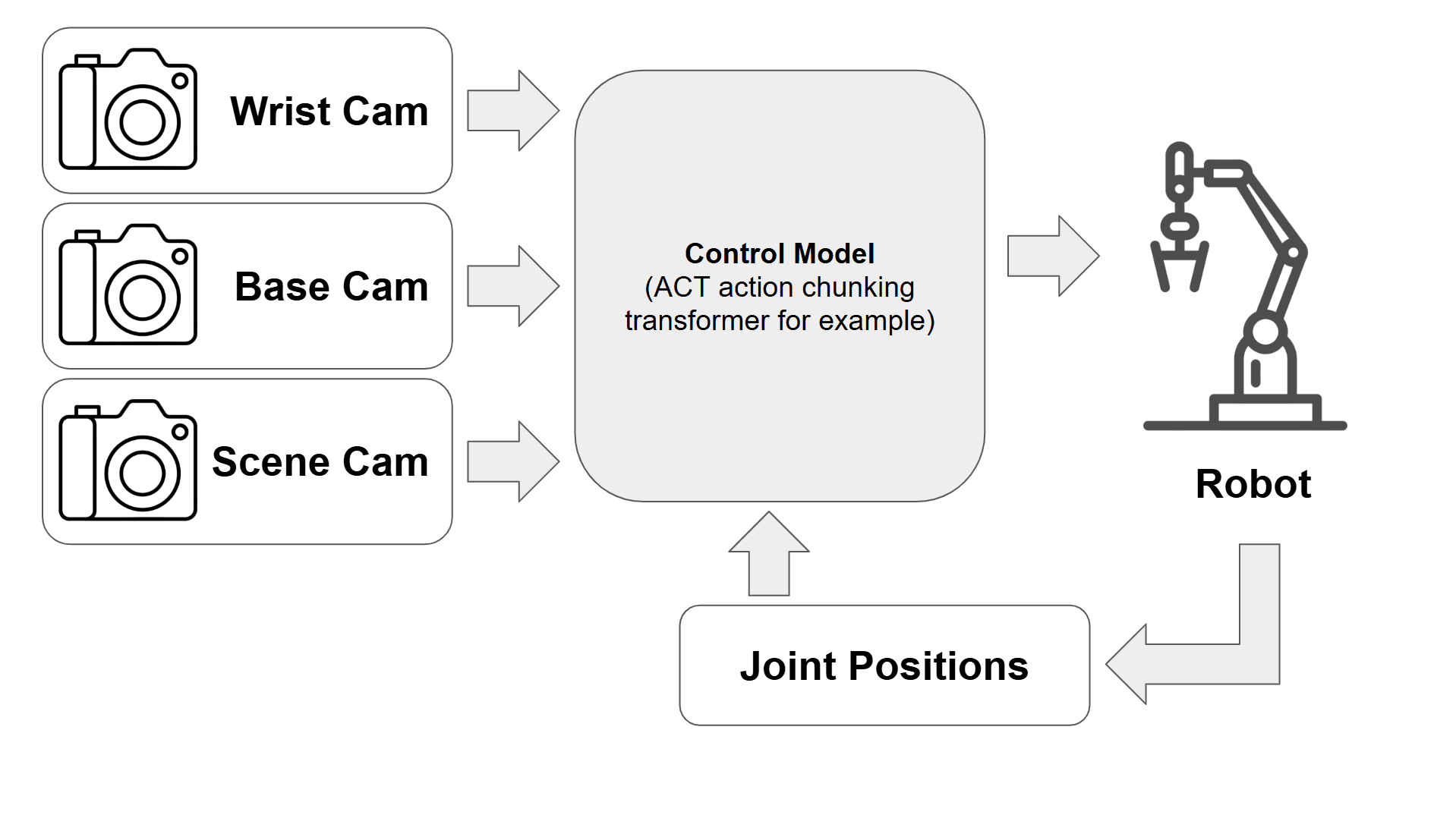
- Collected multi-modal training data including joint angles and synchronized video feeds from three cameras.
- Trained an ACT (Action Chunking Transformer) policy on a Runpod RTX 4090 instance for under $1.
- Successfully trained the robot to pick up a green deodorant roll-on and place it on a red powerbank, achieving ~50% success on the task from just ~50 episodes of training data.
Check out the video above—this was the very first test run! It's fully autonomous and was trained from roughly 15 minutes of human demonstration data.
Setup: I deliberately kept the setup simple: a compact arm workspace, three fixed cameras, and a cheap always-on Linux box to keep the dev loop tight. Keeping the integration friction low makes it incredibly easy to just walk up, collect a bit more data, and kick off a new training experiment.
VR control bridge: To control the arm using my Oculus Quest 1, I whipped up a small localhost web app to act as a WebSocket bridge. The VR controller streams action coordinates to the bridge, and the LeRobot training script subscribes to that exact same stream for synchronous action logging. It’s lightweight, easy to debug, and saves me the hassle (and cost) of building a dedicated physical teleoperation rig.
What's next: The current setup is a solid proof-of-concept, but now it's time to raise the ceiling on success rates, generalization, and task complexity. Most improvements here will come from simply providing better, cleaner demonstrations and controlling the environment. I'm also really eager to experiment with different model architectures. ACT is fast and easy to train, but Vision-Language-Action (VLA) models have shown incredible potential for better generalization.
- Create a cleaner training environment (less background clutter) or introduce deliberately structured, consistent clutter.
- Ensure more consistent lighting, or purposefully vary the lighting and ensure the dataset covers it.
- Capture higher-quality demonstrations: smoother trajectories, less hesitation, and better coverage of edge-case recoveries.
- Lock down camera consistency: fixed exposure, locked white balance, and highly repeatable camera poses.
- Experiment with alternative policy families and compare them against my baseline ACT run with clear metrics.
- Sorting tasks: identifying and placing red bricks in one bin and blue in another from variable starting positions.
- Multi-stage manipulation: pick → place → re-grasp → align (introducing intermediate success criteria).
- Robustness testing: starting the arm from slightly perturbed poses to evaluate its recovery behaviors.
- Data efficiency: figuring out exactly how few demonstrations I can get away with while maintaining a high success rate through good augmentation.